 Deutsch
Deutsch Français
Français Русский
Русский%22%20xlink%3Ahref%3D%22%23CW5aYGFvw6_1381%22%2F%3E%20%3Cuse%20width%3D%2230%22%20height%3D%2220%22%20transform%3D%22matrix(-12.33562%20-20.5871%2020.58684%20-12.33577%20240.3%2048)%22%20xlink%3Ahref%3D%22%23CW5aYGFvw6_1381%22%2F%3E%20%3Cuse%20width%3D%2230%22%20height%3D%2220%22%20transform%3D%22matrix(-3.38573%20-23.75998%2023.75968%20-3.38578%20288%2095.8)%22%20xlink%3Ahref%3D%22%23CW5aYGFvw6_1381%22%2F%3E%20%3Cuse%20width%3D%2230%22%20height%3D%2220%22%20transform%3D%22matrix(6.5991%20-23.0749%2023.0746%206.59919%20288%20168)%22%20xlink%3Ahref%3D%22%23CW5aYGFvw6_1381%22%2F%3E%20%3Cuse%20width%3D%2230%22%20height%3D%2220%22%20transform%3D%22matrix(14.9991%20-18.73557%2018.73533%2014.99929%20240%20216)%22%20xlink%3Ahref%3D%22%23CW5aYGFvw6_1381%22%2F%3E%20%3C%2Fsvg%3E) 简体中文
简体中文What is Freenet? Answer to a question on OnlineSim
- Sep 9, 2023, 8:06 PM
- 12 minutes
The dark side of the internet, part 3: What is Freenet
A regular browser request will not take you into the Dark Web. You will have to configure a special network and submit the correct name of the resource — this is the only way to download content from the Dark Web.
In this article, you will find out through which networks you can access the Dark Web and what type of resources you can find there.
Previous articles:
-
The Dark Web, part 1: What is the Dark Web and what is it used for
-
The Dark Web, part 2: How do .onion sites work
-
The Dark Web, part 3: What is Freenet ← you are here
-
The Dark Web, part 4: What is I2P and how it works
-
The Dark Web, part 5: How to access Darknet via Tor, I2P and Freenet
What is Freenet
Freenet is an anonymous and decentralized peer-to-peer (P2P) network which runs on top of the regular internet. Freenet has no regular servers or hosted websites. In fact, every user’s computer in the Freenet project is a server that stores some of the network information.
For more on P2P network design and operation, please read the article “The Dark Web, part 1: What is the Dark Web and what is it used for”.
Essentially, Freenet is a large data repository and a part of the Dark Web where users upload their data, which then becomes available to all other network users.
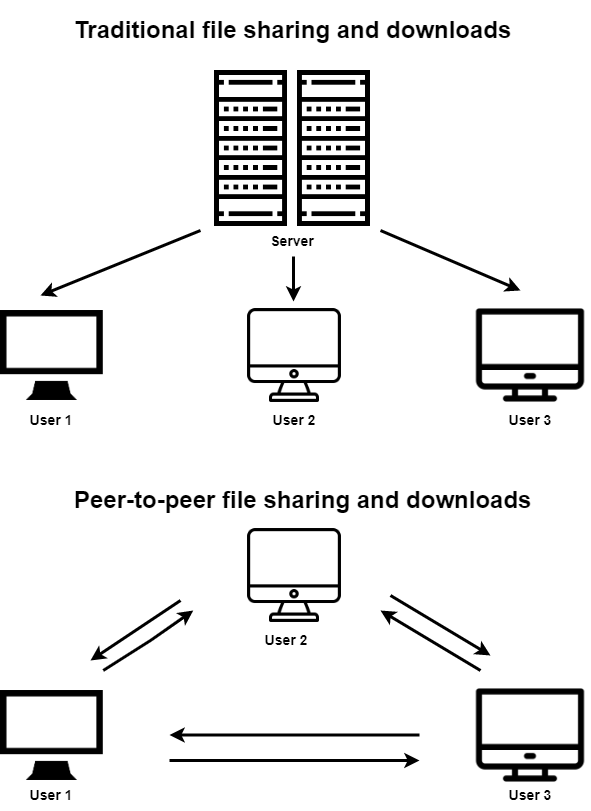
Unlike in other P2P networks, Freenet users have no control over what data is in their data storage. Instead, files are stored or deleted depending on how popular they are. This makes the Freenet a project that is resistant to censorship. There is no such option as a “Delete file” button in Freenet.
Freenet emerged as part of the Dark Web in 2000 and has since been used to spread censored information around the world, including China and the Middle East.
How Freenet works
Each network node is a local repository of information from which users gain read and write access to data, as well as a dynamic routing table. This table contains the addresses of other nodes and the special keys that are expected to be stored in them. This article is about Freenet’s operating principles, and the topic of keys will be covered in another article.
According to the creators' concept, most Freenet members should run their own nodes to protect themselves and other users from accidental use of a hostile external node, and to increase the storage capacity available to the network as a whole. For this, users are expected to contribute their computer’s network resources and part of their hard drive space to run the system and store some information.
Freenet’s operating model can be described as follows: requests for keys are passed from node to node through a chain of proxy nodes, in which each node decides which next node to send the request to.
Routes vary depending on the key type. They will also change over time for each file so network members can download it faster. These route adjustments are determined by the routing algorithms and the network’s operating principle.
Routing can be described as follows: when a user connects to Freenet, he/she loads the addresses of different nodes from a seed node, which is essentially a repository of nodes’ addresses. Then the user creates a network request, which is sent to nodes in search of the requested information.
All communications between nodes are encrypted, any connection between any two nodes goes through several other nodes. This creates anonymity for the originator of the request and the request itself. Node interactions can be compared to a distributed hash table which is needed to search for certain user data.
A hash table is a special data structure for storing pairs of keys and their values. It operates as a function: it takes a certain value (key) as input and returns the address where the requested information is stored.

There is another option to retrieve node addresses, which is to connect to the network of the users you know. To connect to a user you know, you have to personally inquire for his/her node’s ID. When users in a group have exchanged their node IDs and connected between each other, a network forms — it is called “the Freenet Dark Web”. Essentially, this is a way to form a VPN network between a group of users. When a user sends a request with a key into the network, that key passes through a chain of random nodes until a node with the desired information is found. Searching for information on the Dark Web works like this: first, the request goes to one node. If that node does not have the desired information, it redirects the request to another nearest node from its hash table. This repeats until the desired information is found on a network node. When the information is found in a node, that node sends it to the user through another chain of nodes — it doesn’t know who the end recipient is. The transit nodes don’t know how many nodes there are in the chain in front of them or whether the next node is another transit node or the end recipient. Such a routing practice helps to anonymize users and their requests. Stored files are distributed across the network nodes; the more nodes there are in the network and the more space each of them provides on its hard drive, the more files can be stored in the network for longer times. Over time, nodes within groups acquire specialization in what files they store. The Freenet algorithm is designed so that nodes can figure out which node it is best to contact with any specific key. If a node does not have a requested file, the network algorithm will help it figure out which node is best to query for that file and redirect the request to it. When the response arrives, it will pass through that node, and it will keep a copy of the file. Thus, each node keeps copies of files of a certain type or, rather, with a certain key format. This increases the likelihood that the node in the future will be able to faster find the files for similar requests.
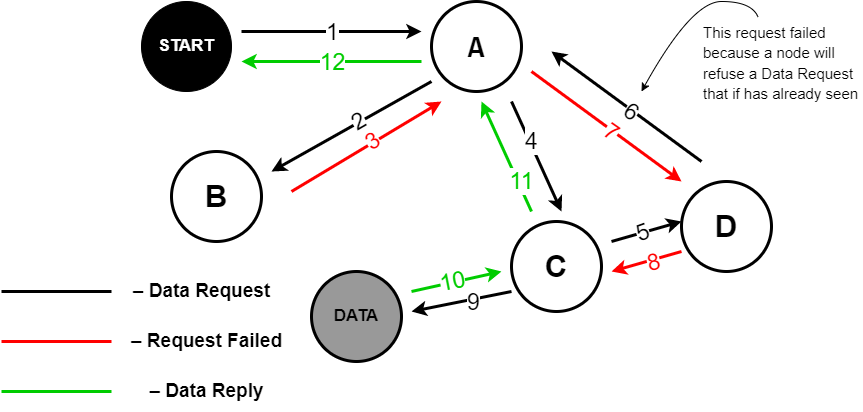
In this diagram, some details are omitted for simplicity. One such detail is as follows. A request first goes to several random Freenet nodes in search of the required file. The latter, in turn, send requests to other nodes from their distributed hash tables. When a node is found that has the required file, it sends it to the requesting user along a chain of nodes. Now, let’s look into the procedure in more detail.
We are in the Start node and need the data from the Data node. The Start node doesn’t know which nodes have the required data and how to reach them. So, the Start node contacts the closest node A and asks if it has the required data.
Node A does not have that data, but it can ask around from other groups of nodes. Thus, it sends a request to a random node it knows. In this case, that is node B. Essentially, node A inquires if node B has the requested data.
Node B replies that it does not have that data and it doesn’t know which nodes may have it. So, node A sends a request to node C asking if it has the data.
Node C replies it does not have it, but it knows two nodes that may have it, and redirects the request to them.
The request goes to node D, but node D does not have the required files, so it redirects the request to another node that may have them. In this example, node D redirects the request to node A, which is the originator of the request. So, node A responds to node D that it is searching for that data as well.
To avoid a loop of nodes A → C → D, each node on the Dark Web keeps a list of nodes that it has contacted with any specific request. Before sending any request, the node checks the list to know if it has already contacted any other node with a specific request.
Node D replies to node C that it has no more nodes it knows, so it has nowhere else to search for that data. Then, node C sends a request to another node it knows — node Data. Node Data sends the required data to node C, node C sends it to node A, and node A sends it to node Start. Thus, the required file has been found and sent to the originator of the request along the same path, but in reverse order.
If a search request is successful, the node returns it with the required data to the previous node in the chain and keeps a copy of the data in its own repository. Besides, it creates a new record in its routing table and associates the actual source of the data with the requested key. With such a routing table, the node will be able in the future to redirect requests to other nodes which are likely to store the required data. To prevent the creation of infinite chains of transit nodes, each search request is assigned a limited number of allowed redirections. That number is defined by the user when sending the request. If the required data was not found within the defined number of allowed redirections, the request fails. Also, each node is assigned an ID so each new redirection in a chain goes to a node that is not yet a part of that group. Each request is assigned a pseudo unique ID so that any node can reject processing a request that it has already reviewed and does not have the required data. Instead, the node redirects the request to a different chain of nodes.
Distributed file storage on Freenet
Uploaded files are divided into fragments (blocks), encrypted and saved randomly on multiple computers in the network. Each data block is copied to several computers.
So, in case any computer storing a specific block goes down or disappears from the network, that block can be recovered from another computer on Freenet.
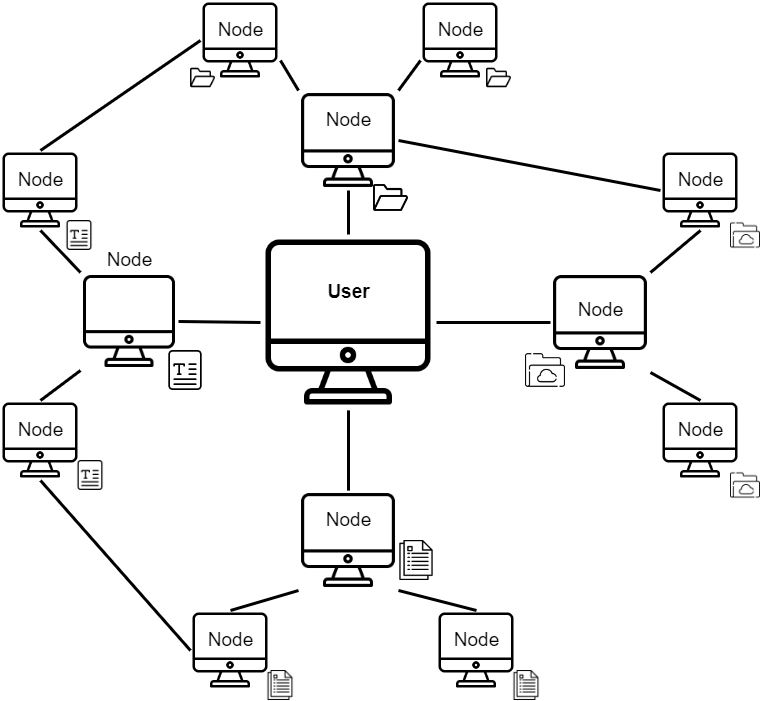
When a user requests a file, its stored pieces are detected on network nodes, recovered and reassembled. This is similar to Torrent: the file storage algorithm contacts the nodes that store pieces of the required file, loads and reassembles them. But there is a difference: on Freenet, several nodes help to find the required file at the same time. A chain is formed: the requesting node → transit node → nodes storing the data. When the required data is found, it goes back along the same chain and is saved on the nodes through which it passes. The more popular a file and the more people store its pieces on their computers, the faster it will download. And if the file is of no interest to anyone, it will eventually disappear from the nodes — they will replace it with more relevant and requested data. That file will not become available until someone uploads it again in its entirety to the network.
Freenet keys
In Freenet, cryptographic keys are used in place of regular URL addresses. When requesting to download a website or some data, you must specify the key for it. The file’s hash code or DSA key acts as such a key.
A hash is a function that performs a mathematical or logical operation on data. As a result, a large amount of information turns into a relatively short string of characters and serves as a data identifier. For example, if two images are different in at least one pixel, their hashes will be different.
DSA is a cryptographic algorithm that uses private and public keys to create an electronic signature and thus attest the authorship of an electronic document. The task of a private key is to create a file signature, and the task of a public key is to verify the signature.
On Freenet, DSA keys create a link between a website and its creator, so no one else can make changes to any site's structure unless he/she has the appropriate DSA keys.
In this article, we will not examine how DSA keys work, as that is a long and difficult topic.
Keys are also required to modify or delete files. There are four types of keys in Freenet:
-
CHK — content hash keys;
-
SSK — signed subspace keys;
-
USK —updatable subspace keys;
-
KSK — keyword signed keys.
CHK are keys that are intended for files with static content, such as .mp3 or PDF documents. A CHK key is the hash of the file’s content.
A typical CHK looks like this:
CHK@SVbD9~[..]X5Brs,bA7qLN[..]Si6bbNQ,AAEA--8
SSK are keys for websites that change over time, e.g. for a news site on which press releases are published on a regular basis. No one can introduce changes to a website unless he/she has the SSK to that site.
A typical SSK looks like this:
SSK@GB3wuHmt[..]o-eHK35w,c63EzO7u[..]3YDduXDs,AQABAAE/mysite-4
USK is designed to hide earlier versions of a website and show only the latest one. It works like this: when you visit a site, USK accesses the list of the site’s versions, finds the latest one and makes sure it is downloaded.
An example of USK:
USK@GB3wuHmt[..]o-eHK35w,c63EzO7u[..]3YDduXDs,AQABAAE/mysite/5/
KSK helps you save pages on Freenet. A KSK address looks like this:
KSK@myfile.txt
Security on Freenet
Security in the Freenet project is created by several methods:
-
Any file is divided into several pieces, which are encrypted and stored on nodes. This ensures that no one can completely remove the file from the network because it is stored on multiple nodes at the same time.
-
None of the nodes can see any request’s path. A node only knows the previous node and the next one to which it passes on the data.
-
Hash tables and private keys must be used to send a network request and receive a response. Thus, hackers cannot intercept traffic by pretending that their node contains the required data. A spoofed node will simply fail validation with a private key and a hash table.
-
Files’ real sources are concealed. Sometimes, a random node with some data may act as its true source, so it is difficult to determine to which node any data was originally uploaded.
One known vulnerability in Freenet security is fake seed nodes. A Freenet user can never be sure that any node that he/she connects to is not malicious, and there is no way to check a node’s reliability. Besides, it is almost impossible to see what is stored on Freenet because each file is concealed and can be divided between different computers.
Another problem is loss of anonymity. The addresses of nodes that often process the same requests may be saved on other nodes. This helps to process new requests, find and download requested data faster.
So, if the authorities or hackers gain access to your computer, make a specific network request and the data is downloaded fast, they can figure out that you have repeatedly reviewed that data before.
Sources that helped us tell you about Freenet
-
Scientific publication Freenet: A Distributed Anonymous Information Storage and Retrieval System
-
An essay on how Freenet works.