 Deutsch
Deutsch Français
Français Русский
Русский%22%20xlink%3Ahref%3D%22%23CW5aYGFvw6_1381%22%2F%3E%20%3Cuse%20width%3D%2230%22%20height%3D%2220%22%20transform%3D%22matrix(-12.33562%20-20.5871%2020.58684%20-12.33577%20240.3%2048)%22%20xlink%3Ahref%3D%22%23CW5aYGFvw6_1381%22%2F%3E%20%3Cuse%20width%3D%2230%22%20height%3D%2220%22%20transform%3D%22matrix(-3.38573%20-23.75998%2023.75968%20-3.38578%20288%2095.8)%22%20xlink%3Ahref%3D%22%23CW5aYGFvw6_1381%22%2F%3E%20%3Cuse%20width%3D%2230%22%20height%3D%2220%22%20transform%3D%22matrix(6.5991%20-23.0749%2023.0746%206.59919%20288%20168)%22%20xlink%3Ahref%3D%22%23CW5aYGFvw6_1381%22%2F%3E%20%3Cuse%20width%3D%2230%22%20height%3D%2220%22%20transform%3D%22matrix(14.9991%20-18.73557%2018.73533%2014.99929%20240%20216)%22%20xlink%3Ahref%3D%22%23CW5aYGFvw6_1381%22%2F%3E%20%3C%2Fsvg%3E) 简体中文
简体中文What is I2P and how it works? Knowledge base on OnlineSim
- Sep 12, 2023, 10:27 PM
- 14 minutes
The dark side of the internet, part 4: What is I2P and how it works
In the last article, we discussed what Freenet and Tor Browser are and what you can do with them on the Dark Web.
In this article, we will look into what I2P is, how it works and what problems it solves.
Previous articles:
-
The Dark Web, part 1: What is the Dark Web and what is it used for
-
The Dark Web, part 2: How do .onion sites work
-
The Dark Web, part 3: What is Freenet
-
The Dark Web, part 4: What is I2P and how it works ← you are here
-
The Dark Web, part 5: How to access Darknet via Tor, I2P and Freenet
What is I2P
I2P is another anonymous peer-to-peer network that runs on top of the regular internet and is not indexed by search engines. I2P is decentralized, so there are no DNS servers — their role is taken by automatically updated "address books". The role of I2P addresses is played by cryptographic keys that do not expose real computers. Every user in the I2P project has his/her key and cannot be tracked.
To learn more about how peer-to-peer networks work, please read the article “The dark side of the internet, part 1: What is the Dark Web and what is it used for”.
I2P started in 2003 as an open source project. Today, it still remains a fully open project developed and supported by enthusiasts from around the world.
How I2P works
All requests are encrypted on the sender side and decrypted on the receiver side using installed algorithms NTCP2 and SSU. These are the cryptic I2P analogs of TCP and UDP, the network protocols that encrypt all data sent to the router.
Therefore, no one, including any intermediary node or any search engine, can intercept a request. An intermediary node has no way to know what happens next to a request it has handled, what the next node does to it, etc.
I2P is made up of:
-
Routers that have both I2P and regular IP addresses. These are essentially interface nodes. Routers are all identical and do not differ from each other.
-
Endpoints — I2P servers or installed clients whose physical locations are unknown.
-
Tunnels — paths along which requests go and which consist of several routers.
Routers and transit nodes are a part of the chain of installed I2P servers which form the tunnel for a request. There is no way for anyone to know which request may pass through any tunnel. Characteristically, it is the user who determines a request’s destination, the length and number of tunnels.
An I2P tunnel can be visualized as an ordinary truck that passes several roadblocks. It doesn't stop at any of them, so no one knows where the truck is going or what it carries. Everyone can look at the truck, but only the recipient roadblock can stop it.
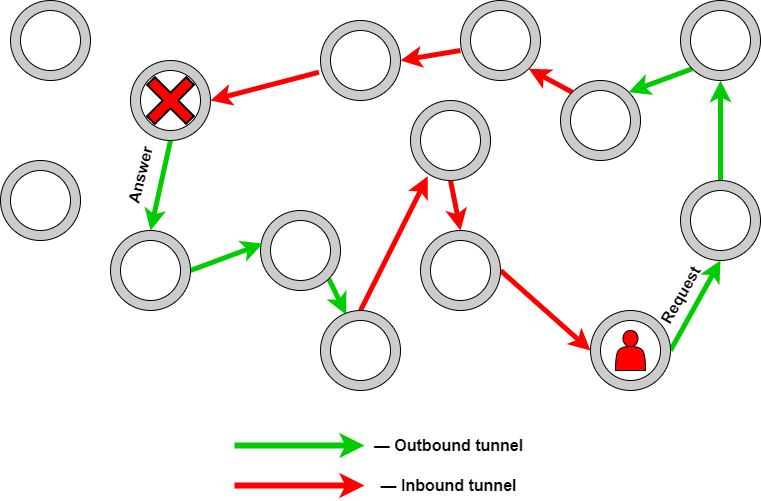
I2P request path: empty circles in the diagram represent routers that are scattered around the world. Green stands for outgoing tunnels, red, inbound tunnels. Continue reading to find out the difference
I2P endpoints are a more complicated entity. Essentially, an endpoint is like a server in a regular network: it is the node to which requests go. However, no one knows that a specific node is an endpoint. Also, no one knows which data is intended for which node. Only an endpoint itself can figure out that it is the intended destination for specific data. Thus, there is no way to figure out the location of an endpoint.
To understand what’s going on, let’s introduce two specific I2P concepts, LeaseSet and Floodfill (aka Routerinfo).
A leaseset is a piece of data in I2P that documents a group of inbound tunnels (so-called leases) and cryptographic keys for a particular client destination.
A floodfill is an installed I2P router that acts as an address book, stores leasesets and knows the locations that the user may look for. If it doesn’t know a specific place, it would reroute the request to another I2P reference service. Any I2P user with the I2P client installed on his/her computer can become a floodfill. To do this, just check the appropriate box in the software settings. We will talk more about I2P settings in the upcoming articles. When a user is looking for anything in I2P, he/she would request a specific leaseset from a random floodfill.
If a floodfill does not know the requested I2P address, it returns the addresses of three other floodfills, and the request goes to them. The latter, in turn, check the leasesets in their databases. This continues until the desired I2P address is found.

The required floodfield is selected based on the target I2P address and the current date. Based on this information, a SHA256 hash is calculated; this produces a set of data which is as long as a regular address.
Then the system looks for a floodfill in the local router database and chooses the one that returns the smallest result of XOR on the data block "target address + date".
Basically, it is a floodfill access function that helps to find the right address. However, the address is generated randomly, so the floodfill provides the addresses of its three neighbors for the user to contact for the required address. The I2P algorithm for selecting a floodfill must use the current date to randomize floodfill requests: with this algorithm, every request for a new address will pass through a new floodfill, and the floodfills will change every day.
An active I2P network node has an average of 5,000 active routers in its database and receives hundreds or even thousands of completely random transit connections.
The role of endpoint addresses is played by IDs that are derived from the public key signature.The hash sum calculates a unique string of a certain length and appends the pseudo domain “.b32.i2p” to it, producing a regular intranet address.
Then, a regular readable domain name is assigned to the intranet address.
Tunnels form a path through a selected list of routers. They are protected by multiple layers of encryption, and each of the routers on the path can only decrypt one layer. The decrypted information contains the IP address of the next router and the next level of encrypted information that will go to the next router.
Information goes one way along tunnels, and each tunnel has a starting and ending point. Another tunnel is required for the return message.
Tunnels operate as follows. First, an outgoing tunnel is built, which consists of several nodes. Each node decrypts a piece of information that contains instructions. The instructions indicate the next node to which to send the information. At the terminal point of the outgoing tunnel, the node decrypts a piece of information that says that the chain is complete.
And since all chains are one-way, the last node receives the inbound tunnel route. As a result, the information returns to the user.

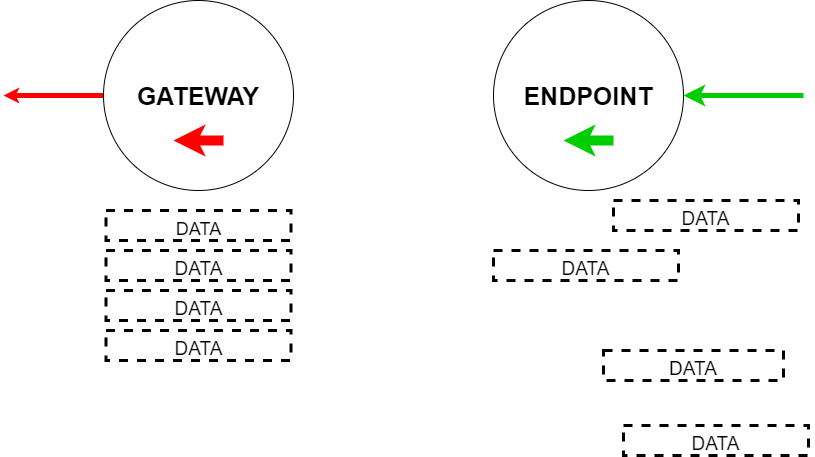
Depending on the tunnel type (inbound or outgoing), the last node is named “endpoint” or “gateway”. An endpoint’s task is to collect fragmented information into a larger data packet and send it via a gateway to the appropriate user.
Let's say Martin wants to send data to John. Martin has an outgoing tunnel that is 4 nodes long, and John has a 5-node inbound tunnel. When Martin sends data, it first goes through the 4 nodes of the outgoing tunnel to the endpoint, then it enters the gateway and goes through John’s inbound tunnel consisting of 5 nodes.
If John decides to send a response to Martin, a new path will be built, and the number of nodes in it will depend on Martin’s and John’s preferences.
The I2P network operates using garlic routing.
How garlic routing works
Garlic routing was developed some 20 years ago. It is a method of building tunnels to send data in which multiple messages are encrypted and bundled into a single request.
Garlic routing is an improved implementation of onion routing and is used in the TOR project. Garlic routing is used when an encrypted message needs to be sent through transit nodes without revealing its content to them or to search engines.
The main difference between the two types of routing is as follows. In onion routing, only one message can be encrypted in a single clove, while in garling routing, several messages can be encrypted in a single clove.

When a message is transmitted using garlic routing, it is encrypted and decrypted as it interacts with each node. At the path creation stage, each node is only provided the routing instructions to reach the next node in the chain.
During the passage of the request, the message is transmitted through the tunnel and is only available to its last node.
Garlic is a block of information that consists of several cloves. Some of them are messages intended for the user, others are transit messages.
For example, when a user wants to send information to another person, it is wrapped in a clove, which is then added to other blocks of information from other network users, forming a garlic. The garlic is encrypted with special algorithms and transmitted to different nodes on the network.


Each garlic contains information for the creator of each clove:
-
Number of the tunnel at the user router (4 random bytes).
-
The next router’s address and the tunnel number at that router.
-
Symmetric encryption key and initialization vector encryption key. An initialization vector (IV) is a (pseudo)random sequence of characters which is added to the encryption key and enhances its security.
-
The node’s role in the chain (transit node or endpoint).
Each clove is identified by the first bytes of the information it contains, which is a part of its address’s hash. When the recipient finds the desired clove, he/she decrypts its content with the cryptographic key. He/she cannot decrypt the information contained in other cloves, as it is intended for other users and protected with other keys.
Summary: interaction between user request and the network
First, the user creates a request, and tunnels are formed for it. The request passes the inbound tunnel via several transit points and arrives at the endpoints → leasesets are required from random floodfills.
Transit points are used so that no one can track the location of the endpoint.
Details of the inbound tunnel arrive at the endpoint along with the request. They are required to make sure that the request with the response can return to the user.
When the request comes to the server, it forms a response and sends it to the user. As tunnels are one-way, the server sends the response through its outgoing tunnel. The recipient's address is the inbound tunnel through which the request came to the server.
Here is what it looks like in an overall diagram.

This may look busy and complicated, so let’s look at the interactions in smaller steps.
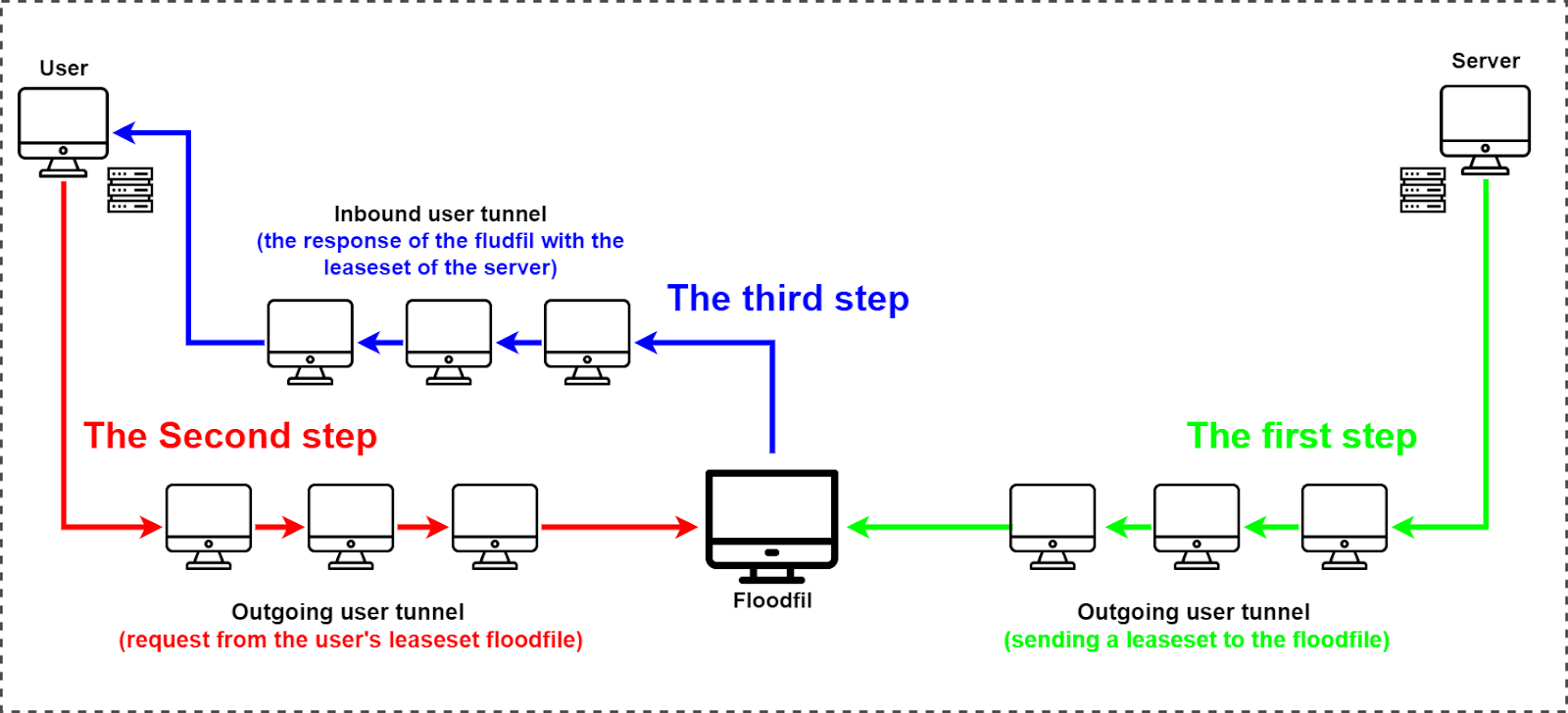
At step 1, the server publishes its leaseset with the floodfill by sending it through the outgoing tunnel.
At step 2, the user wishes to connect to that server. For this, he/she sends a request through his/her outgoing tunnel to the floodfill.
At step 3, the floodfill sends a response to the user’s computer through his/her inbound tunnel.
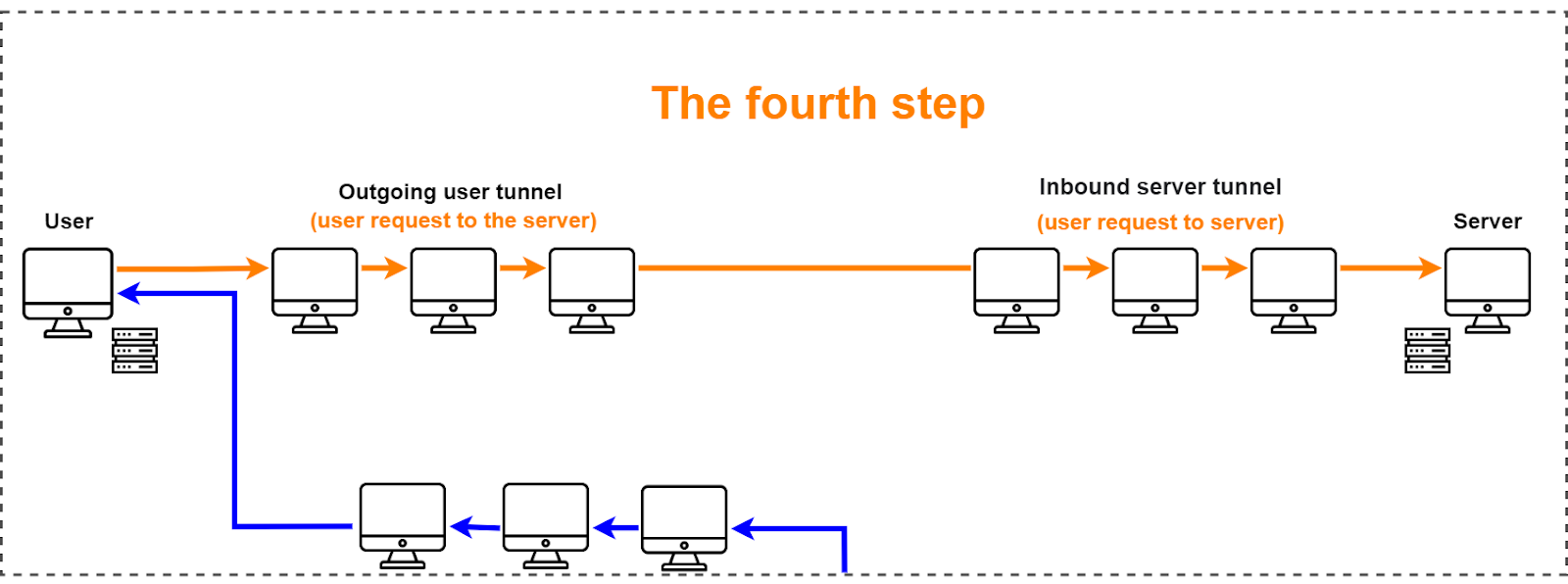
At step 4, the user sends a request to the server. The request goes through the user’s outgoing tunnel and enters the server’s inbound tunnel.
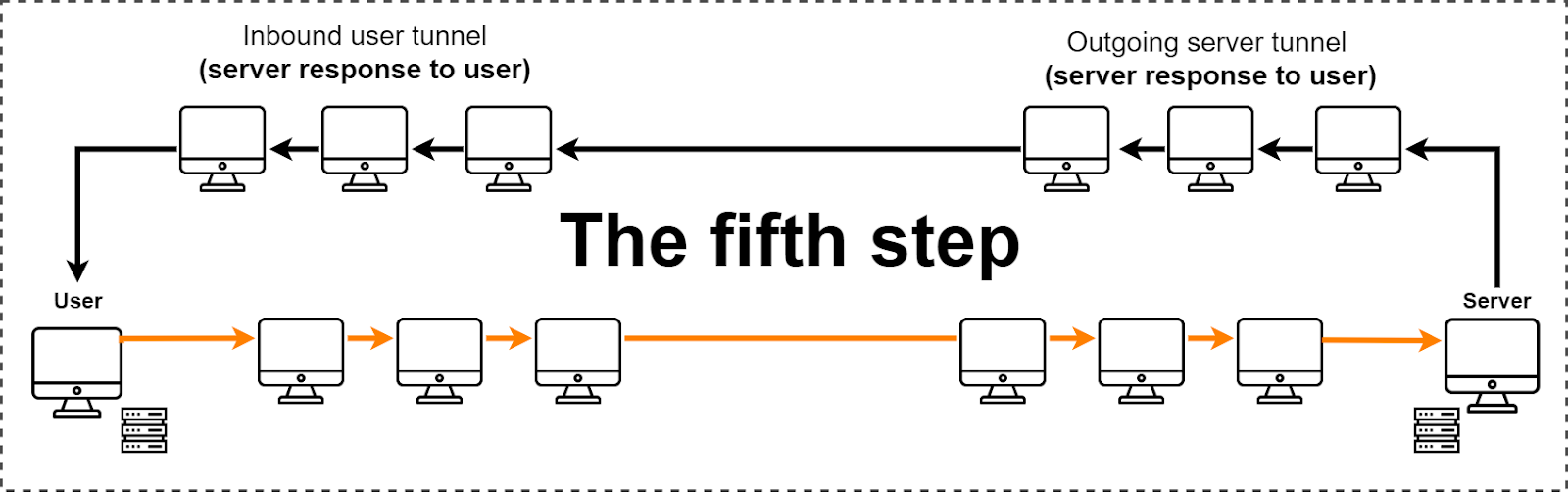
At step 5, the server responds to the user. It sends the response through the server's outgoing tunnel, which then goes into the user's inbound tunnel and ends up on the user's computer. After that, the desired resource opens on the user’s computer.
I2P clients
The I2P network is based on two technologies — Java and C++. Originally, the project was created in Java and named I2P; in 2013, an enthusiast with the nickname Original created an I2P client in C++ and named it I2Pd. The latter is much better than the predecessor, and here is why.
The I2Pd client is architecturally superior to the Java version. This is because I2P contains a lot of cryptography, which is very difficult to implement in Java because of the latter's severe performance restrictions. This problem was addressed by adding libraries written in C to the Java router. However, each call of such a library comes with a large overhead.
As for C++, all cryptography is embedded in the network, runs natively and does not slow down the network .
Apart from faster network operation, routers in I2Pd consume less system resources: the software created in C++ directly interacts with the system, while the Java version runs within a virtual machine acting as a layer between the operating system and the software.
Another I2Pd advantage is fast operation. In the regular I2P, the connection goes through several Java routers, hence requests take longer to handle, and the internet speed does not exceed several dozens of kilobits per second. In I2Pd, requests are handled faster, so the connection speed may go up to 1 Mb/sec.
How I2P is different from Tor
A major difference between the two etworks is that Tor is a etwork of nstalled clients, while 2P is a etwork of servers. This is because Tor's task is to hide the IP address of the installed client who made the request, and 2P s task is to hide the server to which the user request goes. There are more Tor/ 2P differences as shown below:
-
Tunnels are one-way in I2P and two-way in Tor. So, traffic in I2P goes through one tunnel to the recipient and returns to the sender through another.
-
Tor uses onion encryption, and I2P uses garlic encryption. Both encryption types are reliable. However, traffic is protected layer by layer in onion encryption, while it is additionally protected block by block for each user in garlic encryption. Therefore, the final level of protection is higher in garlic encryption.
-
In I2P, no one on the network knows who the source and the recipient is. In Tor, there is an intermediary node that knows where a file comes from and where it should be routed.
-
In case Tor is banned in a specific country, it will be problematic to connect to it — the client won’t be able to find the entry nodes to build a chain and figure out where to send a message.
In I2P, even if a floodfill gets banned, a user can manually specify another floodfill and thus receive a list of network entry nodes. The next time, the user won’t have to specify anything, as the software would know the entry nodes and use them. Therefore, fault tolerance is better in I2P than in Tor.
-
Tor is suitable not only for accessing the darknet, but also for browsing the regular internet. For example, you can use Tor to access regular social media or use streaming services, whereas I2P is designed only for messaging within its network, although I2Pd has nearly all the features of the regular internet.
I2P was originally an open source project developed by enthusiasts. Their goal was to create an anonymous and secure internet. On the other hand, the Tor network was originally conceived by the government which can identify any particular user.
In 2016, the USA introduced amendments into Rule 41, enabling the FBI to hack into any number of computers located anywhere in the world with just a single warrant. As a result, the authorities have the right to hack into the network exit node and access your confidential information. This happened in 2016, when the FBI hacked over 8,000 computers in 120 countries.